Python Web Scraping Application - Scraping PayPal Job Positions

1 Introduction
Not long after the traditional job-hunting season (around March/April in China), the autumn job-hunting season is approaching. In this busy and stressful period of time, I once dreamed of being able to grab all the job positions of my target companies with one click, and then conquer them one by one based on my strengths and job-seeking desires, and get a basketful of offers. In fact, we can easily accomplish the first step of this goal using Python. This article will take the official website of PayPal, a well-known financial technology company, as an example to demonstrate the small technique of automatically scraping job positions with Python, and help you take a faster step on the job-hunting path!
2 Preparation
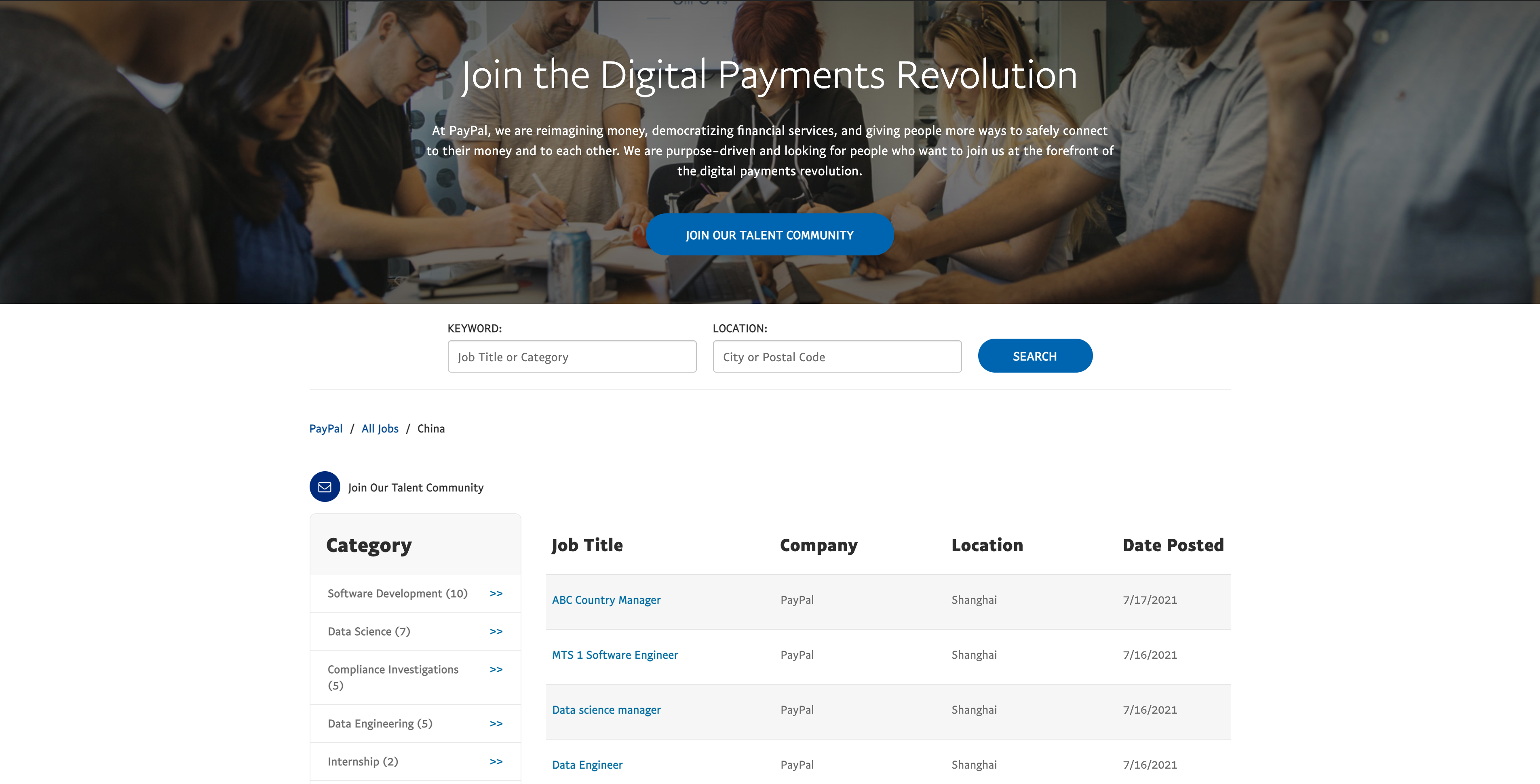
First of all, check the structure of the PayPal job search website. The released job positions are displayed in the form of a list, and clicking on a position in the list will take us to its corresponding details page. At the same time, some job positions in certain countries and regions are relatively large in quantity and are displayed on multiple pages, with URLs distinguished by their corresponding page numbers, such as https://jobsearch.paypal-corp.com/en-US/search?facetcitystate=san%20jose,ca&pagenumber=2. Therefore, we can roughly crawl the details of each job position by performing the following steps:
- Locate the list of job positions and find the URL corresponding to each job position
- Traverse all pages and repeat the above operation to store all job positions URLs
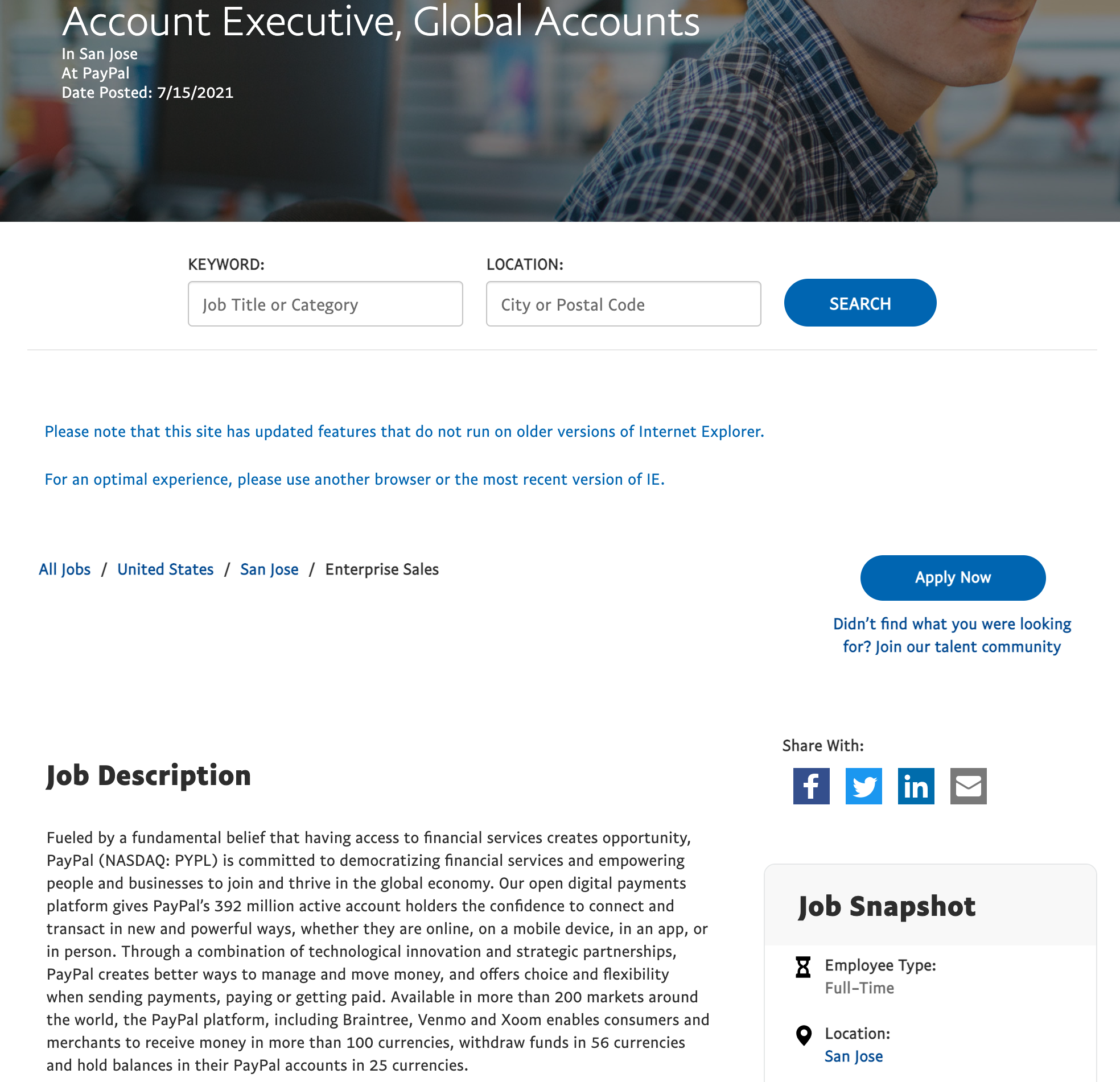
- Access the job position description through the URL of the job position, locate the position of the details, and save the job position description
3 Building the Web Scraper with Python Code
Please refer to the previous article Two-minute Taobao Order Grab Robot for Python environment configuration.
3.1 Importing Dependent Packages
# Parsing web pages
import requests
from bs4 import BeautifulSoup
# Table operation
import numpy as np
import pandas as pd
# Common
import re
import os
import unicodedata
3.2 Accessing the Job Position List
# Request the URL and get the returned result
def url_request(url):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36'}
r = requests.get(url, headers=header)
print('Connection status:', r.status_code, '\n')
return r.text
3.3 Parsing Job Position Categories
# Find the elements needed in the page and store the job position list information
def job_parser(html):
header,desc,link = [[] for i in range(3)]
soup = BeautifulSoup(html, 'html.parser')
# Right-click to open the browser inspector, check the page source code, and you can see that the name of the job position category is "primary-text-color job-result-title", which is an a tag
job_header = soup.find_all('a', attrs={'class': 'primary-text-color job-result-title'})
# Element lookup method is the same as before
job_link = soup.find_all('a', attrs={'class': 'primary-text-color job-result-title'}, href=True)
header = [i.contents[0] for i in job_header]
link = ['https://jobsearch.paypal-corp.com/'+i['href'] for i in job_link]
# Save the result
return pd.DataFrame({'Title':header, 'Link':link})
3.4 Traverse All Pages
# Create a dataframe to store the result
df = pd.DataFrame(columns=['Title','Link'])
# Create a URL template and add different page numbers to match different pages
job_url_header = 'https://jobsearch.paypal-corp.com/en-US/search?facetcountry=cn&facetcity=shanghai&pagenumber='
# Traverse all pages and store the results
for i in range(2):
job_url = job_url_header + str(i+1)
print('URL: {}'.format(job_url))
job_html = url_request(job_url)
# Store the results of each page
df = df.append(job_parser(job_html))
3.5 Scraping Job Position Details
def get_jd(url):
jd_html = url_request(url)
soup = BeautifulSoup(jd_html, 'html.parser')
jd_desc = soup.find('div', attrs={'class': 'jdp-job-description-card content-card'})
# JD formats are different, here are just demonstrations
if jd_desc:
if jd_desc.findAll('ul')[:]:
desc = [i.text + '\n{}'.format(j.text) for i,j in zip(jd_desc.findAll('p')[:], jd_desc.findAll('ul')[:])]
else:
desc = [i.text for i in jd_desc.findAll('p')[:]]
return unicodedata.normalize('NFKD', '\n'.join(i for i in desc))
# Use the detail scraping function on previously stored content, and save detail information.
df['JD'] = df['Link'].apply(get_jd)
# Print the result
df.tail(2)
| Title | Link | JD |
|---|---|---|
| Manager, APAC Portfolio Management | https://jobsearch.paypal-corp.com//en-US/job/manager-apac-portfolio-management/J3N1SM76FQPVMX4VFZG | As the Shanghai Team Manager of PayPal APAC Portfolio Management team in GSR Enterprise Seller Risk Ops, you will manage a team of underwriters, and drive a risk management strategy and framework leveraging your strong business and financial acumen, logical reasoning and communication skills. This role will be covering the markets such as Hong Kong, Taiwan, Korea and Japan, based out of Shanghai. |
| FBO Accountant | https://jobsearch.paypal-corp.com//en-US/job/fbo-accoutant/J3W8C0677G8FLJQQZDL | Responsibilities Timely and effective reconciliation of all assigned General Ledger accounts, including timely and accurate clearing of reconciling items in accordance with Company Policy. Ensure accurate posting of general ledger... |
We can see that we have successfully scraped job position information (with some text truncated). There is other information on the web page, and you can add more information according to your needs.