Built a Chatbot with Streamlit and Llama 2 with Google Colab GPUs from Scratch

So far, we have talked about a lot of things regarding Llama 2:
- Swift inference powered by GPUs
- Thoughtful responses with appropriate prompts
- Question answering utilizing a knowledge database
- A user-friendly web interface
You can find those informative posts in the GenAI section of Spacecraft as below:

This post shows a product that makes the best of all the things learned, and build a web-based chatbot powered by a local Llama 2 model, running on Google Colab with GPUs.
2 Dependencies
Firstly, install a few dependencies:
!pip install -q streamlit
!npm install localtunnel
# GPU setup of LangChain
!CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip install --force-reinstall llama-cpp-python==0.2.28 --no-cache-dir
!pip install huggingface_hub chromadb langchain sentence-transformers pinecone_clientThen download the Llama 2 model to the Colab notebook:
!wget https://huggingface.co/TheBloke/Llama-2-7b-Chat-GGUF/resolve/main/llama-2-7b-chat.Q5_0.gguf3 Build the Web Chatbot
The web chatbot is like this:
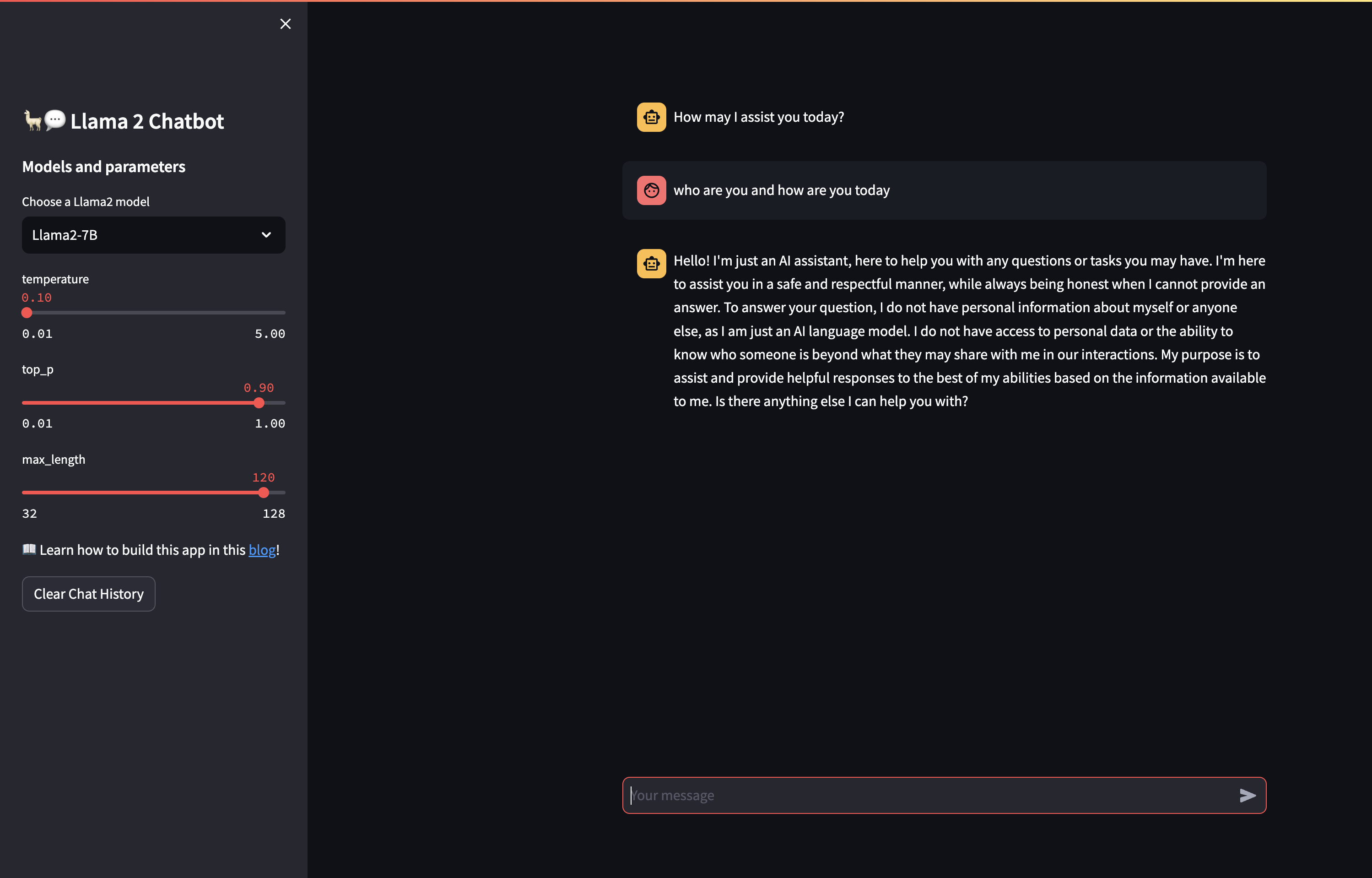
You need to write the app code to the disk first:
%%writefile app.py
import streamlit as st
import os
from langchain.llms import LlamaCpp
from langchain.chains import LLMChain
from langchain.callbacks.manager import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain.prompts import PromptTemplate
from langchain.llms import LlamaCpp
# App title
st.set_page_config(page_title="🦙💬 Llama 2 Chatbot")
llama_model_path = 'llama-2-7b-chat.Q5_0.gguf'
n_gpu_layers = 40 # Change this value based on your model and your GPU VRAM pool.
n_batch = 512 # Should be between 1 and n_ctx, consider the amount of VRAM in your GPU.
# for token-wise streaming so you'll see the answer gets generated token by token when Llama is answering your question
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])
# Replicate Credentials
with st.sidebar:
st.title('🦙💬 Llama 2 Chatbot')
st.subheader('Models and parameters')
selected_model = st.sidebar.selectbox('Choose a Llama2 model', ['Llama2-7B', 'Llama2-13B'], key='selected_model')
if selected_model == 'Llama2-7B':
llm_path = llama_model_path
elif selected_model == 'Llama2-13B':
llm_path = llama_model_path
temperature = st.sidebar.slider('temperature', min_value=0.01, max_value=5.0, value=0.1, step=0.01)
top_p = st.sidebar.slider('top_p', min_value=0.01, max_value=1.0, value=0.9, step=0.01)
max_length = st.sidebar.slider('max_length', min_value=32, max_value=128, value=120, step=8)
st.markdown('📖 Learn how to build this app in this [blog](https://blog.streamlit.io/how-to-build-a-llama-2-chatbot/)!')
llm = LlamaCpp(
model_path=llm_path,
temperature=temperature,
top_p=top_p,
n_ctx=2048,
n_gpu_layers=n_gpu_layers,
n_batch=n_batch,
callback_manager=callback_manager,
verbose=True,
)
# Store LLM generated responses
if "messages" not in st.session_state.keys():
st.session_state.messages = [{"role": "assistant", "content": "How may I assist you today?"}]
# Display or clear chat messages
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.write(message["content"])
def clear_chat_history():
st.session_state.messages = [{"role": "assistant", "content": "How may I assist you today?"}]
st.sidebar.button('Clear Chat History', on_click=clear_chat_history)
# Function for generating LLaMA2 response. Refactored from https://github.com/a16z-infra/llama2-chatbot
def generate_llama2_response(prompt_input):
pre_prompt = """[INST] <<SYS>>
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe.
If you cannot answer the question from the given documents, please state that you do not have an answer.\n
"""
for dict_message in st.session_state.messages:
if dict_message["role"] == "user":
pre_prompt += "User: " + dict_message["content"] + "\n\n"
else:
pre_prompt += "Assistant: " + dict_message["content"] + "\n\n"
prompt = pre_prompt + "User : {question}" + "[\INST]"
llama_prompt = PromptTemplate(template=prompt, input_variables=["question"])
chain = LLMChain(llm=llm, prompt=llama_prompt)
result = chain({
"question": prompt_input
})
return result['text']
# User-provided prompt
if prompt := st.chat_input():
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.write(prompt)
# Generate a new response if last message is not from assistant
if st.session_state.messages[-1]["role"] != "assistant":
with st.chat_message("assistant"):
with st.spinner("Thinking..."):
response = generate_llama2_response(prompt)
placeholder = st.empty()
full_response = ''
for item in response:
full_response += item
placeholder.markdown(full_response)
placeholder.markdown(full_response)
message = {"role": "assistant", "content": full_response}
st.session_state.messages.append(message)3.1 Model Setup
In the code, firstly tweak the params per your hardware, models and objectives:
llama_model_path = 'llama-2-7b-chat.Q5_0.gguf'
n_gpu_layers = 40 # Change this value based on your model and your GPU VRAM pool.
n_batch = 512 # Should be between 1 and n_ctx, consider the amount of VRAM in your GPU.The free version of Colab does not too much memory so here the llama-2-7b-chat.Q5_0.gguf is used but you can use a larger model for better performance.
3.2 Message Management
Then, these are the setup for the display/clear of messages of the chatbot:
# Store LLM generated responses
if "messages" not in st.session_state.keys():
st.session_state.messages = [{"role": "assistant", "content": "How may I assist you today?"}]
# Display or clear chat messages
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.write(message["content"])
def clear_chat_history():
st.session_state.messages = [{"role": "assistant", "content": "How may I assist you today?"}]
st.sidebar.button('Clear Chat History', on_click=clear_chat_history)3.3 Get LLM Response
Below function appends the chat history into the prompt and get the response of model:
def generate_llama2_response(prompt_input):
pre_prompt = """[INST] <<SYS>>
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe.
If you cannot answer the question from the given documents, please state that you do not have an answer.\n
"""
for dict_message in st.session_state.messages:
if dict_message["role"] == "user":
pre_prompt += "User: " + dict_message["content"] + "\n\n"
else:
pre_prompt += "Assistant: " + dict_message["content"] + "\n\n"
prompt = pre_prompt + "User : {question}" + "[\INST]"
llama_prompt = PromptTemplate(template=prompt, input_variables=["question"])
chain = LLMChain(llm=llm, prompt=llama_prompt)
result = chain({
"question": prompt_input
})
return result['text']3.4 Conversation
Below shows the question and answering process, the chatbot responses to users' questions:
# User-provided prompt
if prompt := st.chat_input():
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.write(prompt)
# Generate a new response if last message is not from assistant
if st.session_state.messages[-1]["role"] != "assistant":
with st.chat_message("assistant"):
with st.spinner("Thinking..."):
response = generate_llama2_response(prompt)
placeholder = st.empty()
full_response = ''
for item in response:
full_response += item
placeholder.markdown(full_response)
placeholder.markdown(full_response)
message = {"role": "assistant", "content": full_response}
st.session_state.messages.append(message)4 Start the Chatbot
You can bring up the chatbot by using below command:
!streamlit run app.py --server.address=localhost &>/content/logs.txt &
import urllib
print("Password/Enpoint IP for localtunnel is:",urllib.request.urlopen('https://ipv4.icanhazip.com').read().decode('utf8').strip("\n"))
!npx localtunnel --port 8501The result shows a password to access the web app:
Password/Enpoint IP for localtunnel is: 35.185.197.1
npx: installed 22 in 2.393s
your url is: https://hot-pets-chew.loca.ltGo to that url and enter the password, and enjoy the time!
5 Conclusion
This post consolidates information to transform your local Llama 2 model into a fully functional chatbot. Moreover, you have the flexibility to craft specialized assistants for distinct domains by customizing the system prompts, all at no additional cost.
Let's build something cool!