Neo4J Graph Database Anti-Fraud Analysis in Practice (II) - Prepare Data

1 Introduction
In the previous article Neo4J Graph Database Anti-Fraud Analysis in Practice (Part 1) - Setup Analysis Environment, we introduced the Neo4J analysis platform and some basic operations of graph databases. In this article, we will officially start the exploration of the anti-fraud theme. The primary task is to clarify the goal, obtain and sort the data. The example provided by Neo4J focuses on fraudsters using the same entity information to control a large number of accounts to conduct fraudulent transactions. Therefore, the goal is to find the connections between these accounts and expose the criminal gangs. However, the example did not introduce the source and preparation of the data, which is actually vital in real work. Therefore, this article will focus on the data preparation part.
2 Obtain Data
Neo4J provides various methods to connect to the data repository:
- Manually define the data
- Import CSV file
- Use API to import data
- Import data from a relational database
- Use an application-driven connection to import data (supporting multiple programming languages such as .Net, Java, JavaScript, Go, and Python, etc.)
Personally, I prefer to use Python driver to import data because usually, we can first obtain the raw data in the relational database through Python, process it, and then use the Neo4J interface to connect multiple platforms to complete the data transfer work. In the face of large-scale data sets, using PySpark can further improve computing performance. Neo4J also provides PySpark interface, with very fast read and write speed. Here is an example PySpark code. Note that you need to download the corresponding Neo4j Connector for Apache Spark Jar file before using it.
# Read data from Neo4J
# Replace the account name and password with your own settings
df = spark.read.format("org.neo4j.spark.DataSource")\
.option("url", "bolt+s://63d2d43273493b399454b26961152ed9.neo4jsandbox.com:7687")\
.option("authentication.type", "basic")\
.option("authentication.basic.username", "neo4j")\
.option("authentication.basic.password", "password")\
.option("labels", "Person")\
.load()
display(df)
# Write data to Neo4J
df2 = spark.createDataFrame( [(1, "John"),(2, "Thomas")],
["id", "name"]
)
df2.write.format("org.neo4j.spark.DataSource")\
.option("url", "bolt+s://63d2d43273493b399454b26961152ed9.neo4jsandbox.com:7687")\
.option("authentication.type", "basic")\
.option("authentication.basic.username", "neo4j")\
.option("authentication.basic.password", "password")\
.option("labels", ":Person")\
.option("node.keys", "id")\
.mode("Overwrite")\
.save()
Remember to define an index before loading the data. This operation will significantly improve the program running speed.
3 Define Nodes and Relationships
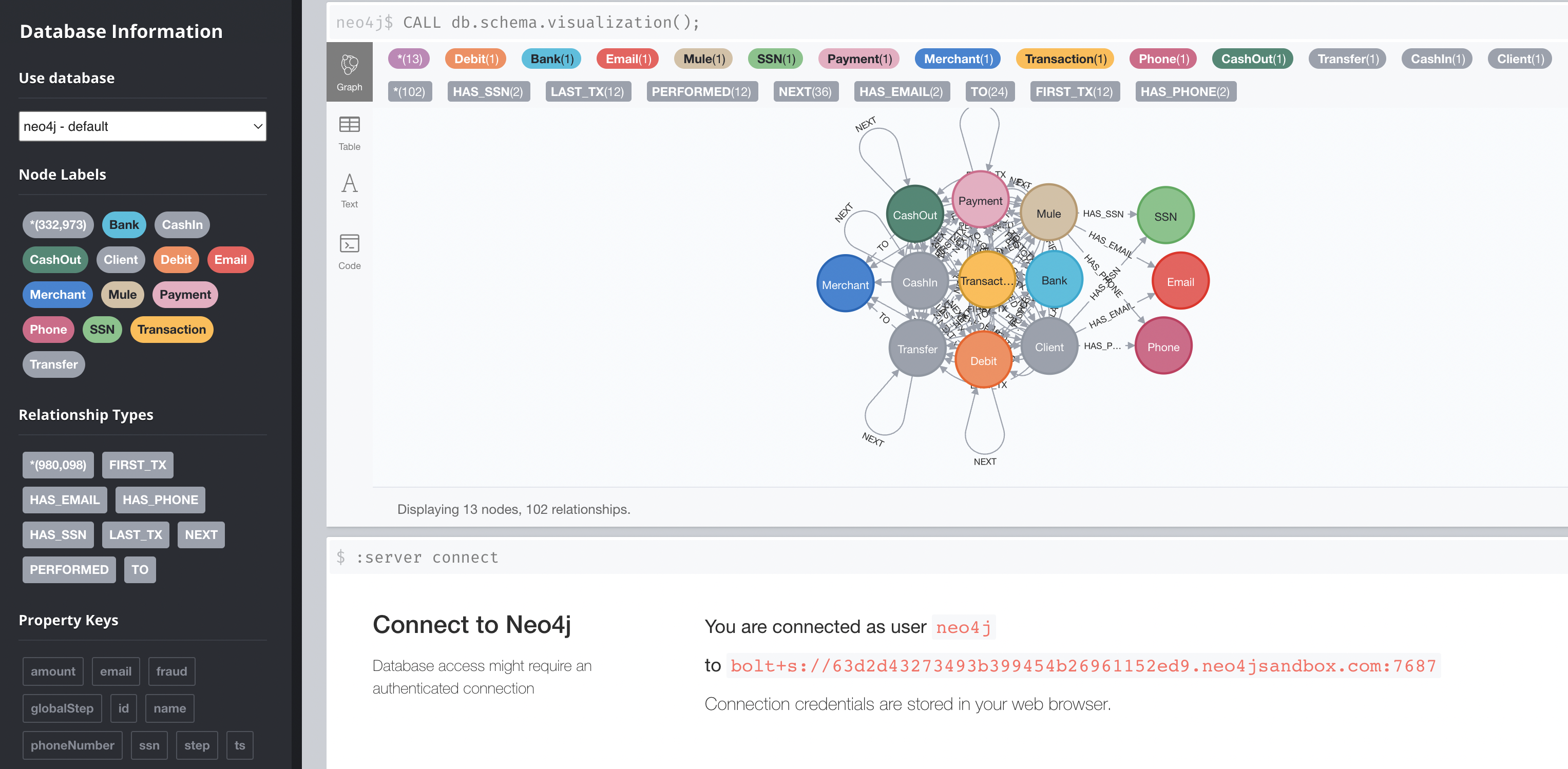
As shown in the figure, the colored circles represent nodes, and the lines between nodes are their relationships. Intuitively, the raw data is a table, which contains some fields related to the target, and each field corresponds to an entity (node).
| Mule | Phone | |
|---|---|---|
| John | 888888888 | demo@gmail.com |
| Tim | 777777777 | demo2@gmail.com |
Nodes can be written into Neo4J using the above code, and the relationships between entities that are useful for the goal can be defined using Cypher. For example, the fact that John has his own email can be defined as follows:
MATCH
(a:Mule),
(b:Email)
WHERE a.Email = b.Email
CREATE (a)-[r:HAS_EMAIL]->(b)
RETURN type(r)
By analogy, relationships useful for the target can be defined in such a way.
4 Data Overview
The first part of the anti-fraud example described the descriptive analysis of the data, such as the number of nodes and relationships, etc. This is helpful for understanding the data, checking data completeness, and ensuring that the data you need is stored in Neo4J according to the set goal. This module's content is relatively intuitive and will not be elaborated further.
5 Conclusion
This article solved many of the initial doubts of graph database beginners, how to import data (usually tables) into Neo4J, and define nodes and relationships that serve the goal. Undoubtedly, this is the foundation of subsequent analysis work, and we can officially analyze the data for anti-fraud. I hope that this sharing will be helpful to you, and welcome to leave a message for discussion in the comments!