Build a Regulation Assistant Powered by Llama 2 and Streamlit with Google Colab GPUs

In our previous discussion, we explored the concept of creating a web chatbot using Llama 2. However, an incredibly practical application of chatbots is their ability to field questions within specific domains of knowledge. For example, a chatbot can be trained on policies, regulations, and laws, effectively functioning as a knowledge assistant that users can collaborate with. This functionality holds significant value for enterprise users, who often have vast repositories of internal documents that can be utilized to train the chatbot. Employees can then leverage the chatbot as a quick reference tool.
Furthermore, this solution can be entirely constructed using open-source components, eliminating the need to rely on external APIs like OpenAI and alleviating any privacy concerns.
This post showcases a compliance assistant built with the utilization of the open-source large language model Llama 2, in conjunction with retrieval-augmented generation (RAG), all presented through a user-friendly web interface powered by Streamlit.
1 Dependencies
Firstly, install a few dependencies:
!pip install -q streamlit
!npm install localtunnel
# GPU setup of LangChain
!CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip install --force-reinstall llama-cpp-python==0.2.28 --no-cache-dir
!pip install huggingface_hub chromadb langchain sentence-transformers pypdf Then download the Llama 2 model to the Colab notebook:
!wget https://huggingface.co/TheBloke/Llama-2-7b-Chat-GGUF/resolve/main/llama-2-7b-chat.Q5_0.gguf1.1 Mount the Google Drive
This chatbot needs to retrieve documents from a vector database which is composed of embeddings of regulations PDFs. The PDFs are saved in Google Drive, so let's mount the Google Drive so the code can access the PDFs:
# Mount the google drive
from google.colab import drive
drive.mount('/gdrive')2 Build the Web Chatbot
The web chatbot is like this:
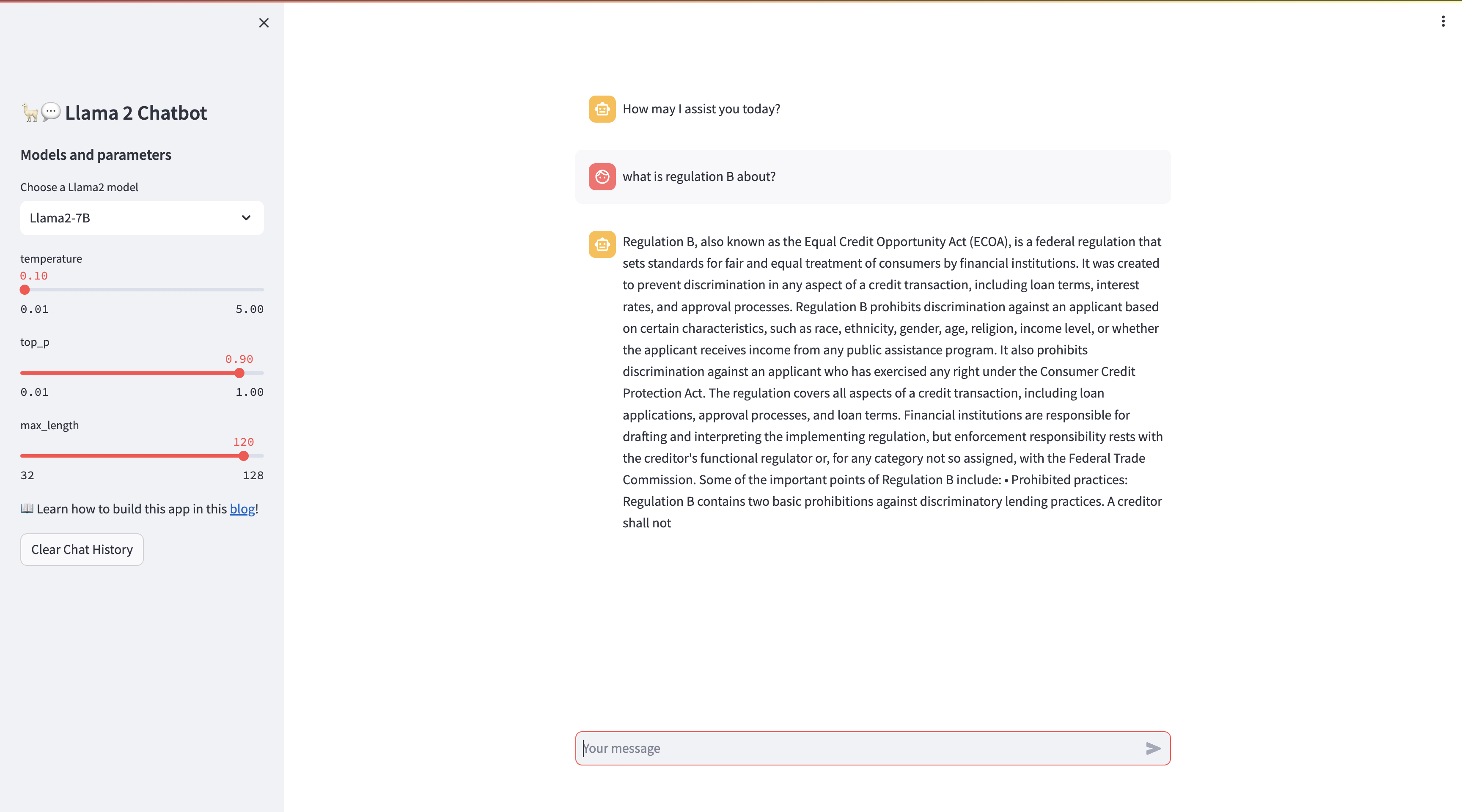
Below is the entire code to build the compliance assistant, the details of each part will be introduced in the follow section:
%%writefile app.py
import streamlit as st
import os
from langchain.llms import LlamaCpp
from langchain.chains import LLMChain
from langchain.callbacks.manager import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain.prompts import PromptTemplate
from langchain.llms import LlamaCpp
from langchain_community.document_loaders import PyPDFLoader, PyPDFDirectoryLoader
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
# App title
st.set_page_config(page_title="🦙💬 Llama 2 Chatbot")
llama_model_path = 'llama-2-7b-chat.Q5_0.gguf'
n_gpu_layers = 40 # Change this value based on your model and your GPU VRAM pool.
n_batch = 512 # Should be between 1 and n_ctx, consider the amount of VRAM in your GPU.
# for token-wise streaming so you'll see the answer gets generated token by token when Llama is answering your question
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])
# ====================== RAG ======================
# Encoding the PDFs
pdf_folder_path = '/gdrive/MyDrive/Research/Data/GenAI/PDFs'
loader = PyPDFDirectoryLoader(pdf_folder_path)
documents = loader.load()
#splitting the text into
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
texts = text_splitter.split_documents(documents)
# Create vector DB, embed and store the texts
# Supplying a persist_directory will store the embeddings on disk
persist_directory = 'db'
## here we are using OpenAI embeddings but in future we will swap out to local embeddings
embedding = HuggingFaceEmbeddings()
vectordb = Chroma.from_documents(documents=texts,
embedding=embedding,
persist_directory=persist_directory)
retriever = vectordb.as_retriever(search_kwargs={"k": 5})
# ====================== App ======================
with st.sidebar:
st.title('🦙💬 Llama 2 Chatbot')
st.subheader('Models and parameters')
selected_model = st.sidebar.selectbox('Choose a Llama2 model', ['Llama2-7B', 'Llama2-13B'], key='selected_model')
if selected_model == 'Llama2-7B':
llm_path = llama_model_path
elif selected_model == 'Llama2-13B':
llm_path = llama_model_path
temperature = st.sidebar.slider('temperature', min_value=0.01, max_value=5.0, value=0.1, step=0.01)
top_p = st.sidebar.slider('top_p', min_value=0.01, max_value=1.0, value=0.9, step=0.01)
max_length = st.sidebar.slider('max_length', min_value=32, max_value=128, value=120, step=8)
st.markdown('📖 Learn how to build this app in this [blog](https://blog.streamlit.io/how-to-build-a-llama-2-chatbot/)!')
llm = LlamaCpp(
model_path=llm_path,
temperature=temperature,
top_p=top_p,
n_ctx=2048,
n_gpu_layers=n_gpu_layers,
n_batch=n_batch,
callback_manager=callback_manager,
verbose=True,
)
# use another LangChain's chain, RetrievalQA, to associate Llama with the loaded documents stored in the vector db
# Store LLM generated responses
if "messages" not in st.session_state.keys():
st.session_state.messages = [{"role": "assistant", "content": "How may I assist you today?"}]
# Display or clear chat messages
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.write(message["content"])
def clear_chat_history():
st.session_state.messages = [{"role": "assistant", "content": "How may I assist you today?"}]
st.sidebar.button('Clear Chat History', on_click=clear_chat_history)
# Function for generating LLaMA2 response. Refactored from https://github.com/a16z-infra/llama2-chatbot
def generate_llama2_response(prompt_input):
pre_prompt = """[INST] <<SYS>>
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe.
If you cannot answer the question from the given documents, please state that you do not have an answer.\n
"""
for dict_message in st.session_state.messages:
if dict_message["role"] == "user":
pre_prompt += "User: " + dict_message["content"] + "\n\n"
else:
pre_prompt += "Assistant: " + dict_message["content"] + "\n\n"
prompt = pre_prompt + "{context}User : {question}" + "[\INST]"
llama_prompt = PromptTemplate(template=prompt, input_variables=["context","question"])
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=retriever,
chain_type_kwargs={"prompt": llama_prompt}
)
result = qa_chain.run({
"query": prompt_input})
return result
# User-provided prompt
if prompt := st.chat_input():
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.write(prompt)
# Generate a new response if last message is not from assistant
if st.session_state.messages[-1]["role"] != "assistant":
with st.chat_message("assistant"):
with st.spinner("Thinking..."):
response = generate_llama2_response(prompt)
placeholder = st.empty()
full_response = ''
for item in response:
full_response += item
placeholder.markdown(full_response)
placeholder.markdown(full_response)
message = {"role": "assistant", "content": full_response}
st.session_state.messages.append(message)2.1 Model Setup
In the code, firstly tweak the params per your hardware, models and objectives:
llama_model_path = 'llama-2-7b-chat.Q5_0.gguf'
n_gpu_layers = 40 # Change this value based on your model and your GPU VRAM pool.
n_batch = 512 # Should be between 1 and n_ctx, consider the amount of VRAM in your GPU.The free version of Colab does not have too much memory so here the llama-2-7b-chat.Q5_0.gguf is used but you can use a larger model for better performance.
2.2 Vector Database
In order to perform RAG, a vector database has to be created first, in this example, the code read the regulation B and regulation Z PDFs and embed them, then a vector database is created based on that:
# ====================== RAG ======================
# Encoding the PDFs
pdf_folder_path = '/gdrive/MyDrive/Research/Data/GenAI/PDFs'
loader = PyPDFDirectoryLoader(pdf_folder_path)
documents = loader.load()
#splitting the text into
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
texts = text_splitter.split_documents(documents)
# Create vector DB, embed and store the texts
# Supplying a persist_directory will store the embeddings on disk
persist_directory = 'db'
## here we are using OpenAI embeddings but in future we will swap out to local embeddings
embedding = HuggingFaceEmbeddings()
vectordb = Chroma.from_documents(documents=texts,
embedding=embedding,
persist_directory=persist_directory)
retriever = vectordb.as_retriever(search_kwargs={"k": 5})
2.3 Message Management
Then, these are the setup for the display/clear of messages of the chatbot:
# Store LLM generated responses
if "messages" not in st.session_state.keys():
st.session_state.messages = [{"role": "assistant", "content": "How may I assist you today?"}]
# Display or clear chat messages
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.write(message["content"])
def clear_chat_history():
st.session_state.messages = [{"role": "assistant", "content": "How may I assist you today?"}]
st.sidebar.button('Clear Chat History', on_click=clear_chat_history)2.4 Get LLM Response
Below function appends the chat history into the prompt and use the vector database created above to retrieve answers.
# Function for generating LLaMA2 response based on RAG.
def generate_llama2_response(prompt_input):
pre_prompt = """[INST] <<SYS>>
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe.
If you cannot answer the question from the given documents, please state that you do not have an answer.\n
"""
for dict_message in st.session_state.messages:
if dict_message["role"] == "user":
pre_prompt += "User: " + dict_message["content"] + "\n\n"
else:
pre_prompt += "Assistant: " + dict_message["content"] + "\n\n"
prompt = pre_prompt + "{context}User : {question}" + "[\INST]"
llama_prompt = PromptTemplate(template=prompt, input_variables=["context","question"])
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=retriever,
chain_type_kwargs={"prompt": llama_prompt}
)
result = qa_chain.run({
"query": prompt_input})
return result2.5 Conversation
Below shows the question and answering process, the chatbot responses to users' questions:
# User-provided prompt
if prompt := st.chat_input():
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.write(prompt)
# Generate a new response if last message is not from assistant
if st.session_state.messages[-1]["role"] != "assistant":
with st.chat_message("assistant"):
with st.spinner("Thinking..."):
response = generate_llama2_response(prompt)
placeholder = st.empty()
full_response = ''
for item in response:
full_response += item
placeholder.markdown(full_response)
placeholder.markdown(full_response)
message = {"role": "assistant", "content": full_response}
st.session_state.messages.append(message)3 Start the Chatbot
You can bring up the chatbot by using below command:
!streamlit run app.py --server.address=localhost &>/content/logs.txt &
import urllib
print("Password/Enpoint IP for localtunnel is:",urllib.request.urlopen('https://ipv4.icanhazip.com').read().decode('utf8').strip("\n"))
!npx localtunnel --port 8501The result shows a password to access the web app:
Password/Enpoint IP for localtunnel is: 34.125.220.166
npx: installed 22 in 2.393s
your url is: https://hot-pets-chew.loca.ltGo to that url and enter the password, and enjoy the time!
4 Summary
This post demonstrates the construction of a versatile chatbot capable of more than just conversation. Specifically, it covers the following key features:
- Creation of a vector database utilizing domain knowledge.
- Ability of the chatbot to retrieve information from the vector database and respond to user queries.
- User-friendly interface for ease of use.
This approach is scalable across various applications, as chatbots excel in information retrieval when equipped with a reliable database as the source of truth. Stay tuned for further insights into valuable applications of this technology.