AMEX - Default Prediction Kaggle Competition Summary

1 Overview
American Express (AMEX), a famous financial services company in the United States, hosted a data science competition on Kaggle, requiring participants to predict whether cardholders will default in the future based on credit card billing data. Each feature has been anonymized, and AMEX provided explanations for the feature prefixes:
D_* = Variables related to defaults
S_* = Variables related to spending
P_* = Repayment information
B_* = Debt information
R_* = Risk-related variables
The following table is a demonstration of the competition data (values are fictional, for reference only):
| customer_ID | S_2 | P_2 | ... | B_2 | D_41 | target |
|---|---|---|---|---|---|---|
| 000002399d6bd597023 | 2017-04-07 | 0.9366 | ... | 0.1243 | 0.2824 | 1 |
| 0000099d6bd597052ca | 2017-03-32 | 0.3466 | ... | 0.5155 | 0.0087 | 0 |
The features 'B_30', 'B_38', 'D_114', 'D_116', 'D_117', 'D_120', 'D_126', 'D_63', 'D_64', 'D_66', 'D_68' are categorical data. The goal of the competition is to predict the likelihood of each customer_ID defaulting in the future (target = 1; otherwise target = 0). The negative samples have been undersampled at a rate of 5%. The competition has already concluded, and this article summarizes the selected publicly available code solutions and discussions to learn from the excellent ideas and implementations in the community.
2 Preparation
Since the data size is large compared to the experimental environment provided by Kaggle, some work was focused on optimizing memory usage. For example, AMEX data - integer dtypes - parquet format converts floating-point data to integer type and stores the data in the parquet format, effectively reducing memory overhead. Similar data compression solutions include AMEX-Feather-Dataset.
60M sample_submission.csv
32G test_data.csv
16G train_data.csv
30M train_labels.csv
Meanwhile, the evaluation metrics for this competition are customized and incorporate the top 4% capture and gini concepts. Many solutions reference the code from Amex Competition Metric (Python) and Metric without DF to evaluate the model performance.
3. Exploratory Data Analysis
Before modeling the data, it is crucial to gain a thorough understanding of it. Exploratory Data Analysis (EDA) forms the foundation for many subsequent tasks in the AMEX competition. Kagglers' focus during this stage includes:
- Checking for missing values
- Identifying duplicate records
- Analyzing the distribution of labels
- Examining the number of credit card bills per customer and their billing dates
- Exploring the distribution of categorical and numerical variables and identifying potential outliers
- Investigating the correlation between features
- Identifying artificial noise
- Comparing feature distributions between the training and testing sets
Some highly-rated notebooks related to these analyses are:
- Time Series EDA
- AMEX EDA which makes sense
- American Express EDA
- Understanding NA values in AMEX competition
4. Feature Engineering & Modeling
4.1 Feature Engineering
Since the data consists of credit card bills where each customer has multiple bills, merging the data from different time periods into a unified format has been a focal point for many solutions. Some approaches include:
- For continuous variables, calculating statistics such as mean, standard deviation, minimum, maximum, and the value of the most recent bill for each feature across all time periods on a per-customer basis. Additionally, calculating the difference and ratio between the most recent and initial bill features.
- For categorical variables, counting the occurrences of each feature value on a per-customer basis across all time periods, and considering the value of the most recent bill. Converting these features into numerical variables, followed by encoding based on the model type (or letting the model handle the encoding automatically).
Relevant high-scoring notebooks related to feature engineering include:
4.2 Model Design, Training, and Inference
The high-scoring solutions in the AMEX competition predominantly use models such as XGBoost, LightGBM, CatBoost, Transformer, TabNet, and ensembles of these models. Different Kaggle experts have employed various techniques to improve their scores. Let's discuss some high-scoring approaches.
Chris Deotte, a Kaggle Grandmaster working at Nvidia, has contributed several foundational solutions, such as XGBoost Starter, TensorFlow GRU Starter, and TensorFlow Transformer Starter. These serve as good starting points for the community. Chris's final solution, which ranked 15th out of 4875, involved using Transformer with LightGBM knowledge distillation. You can find more details in 15th Place Gold – NN Transformer using LGBM Knowledge Distillation.
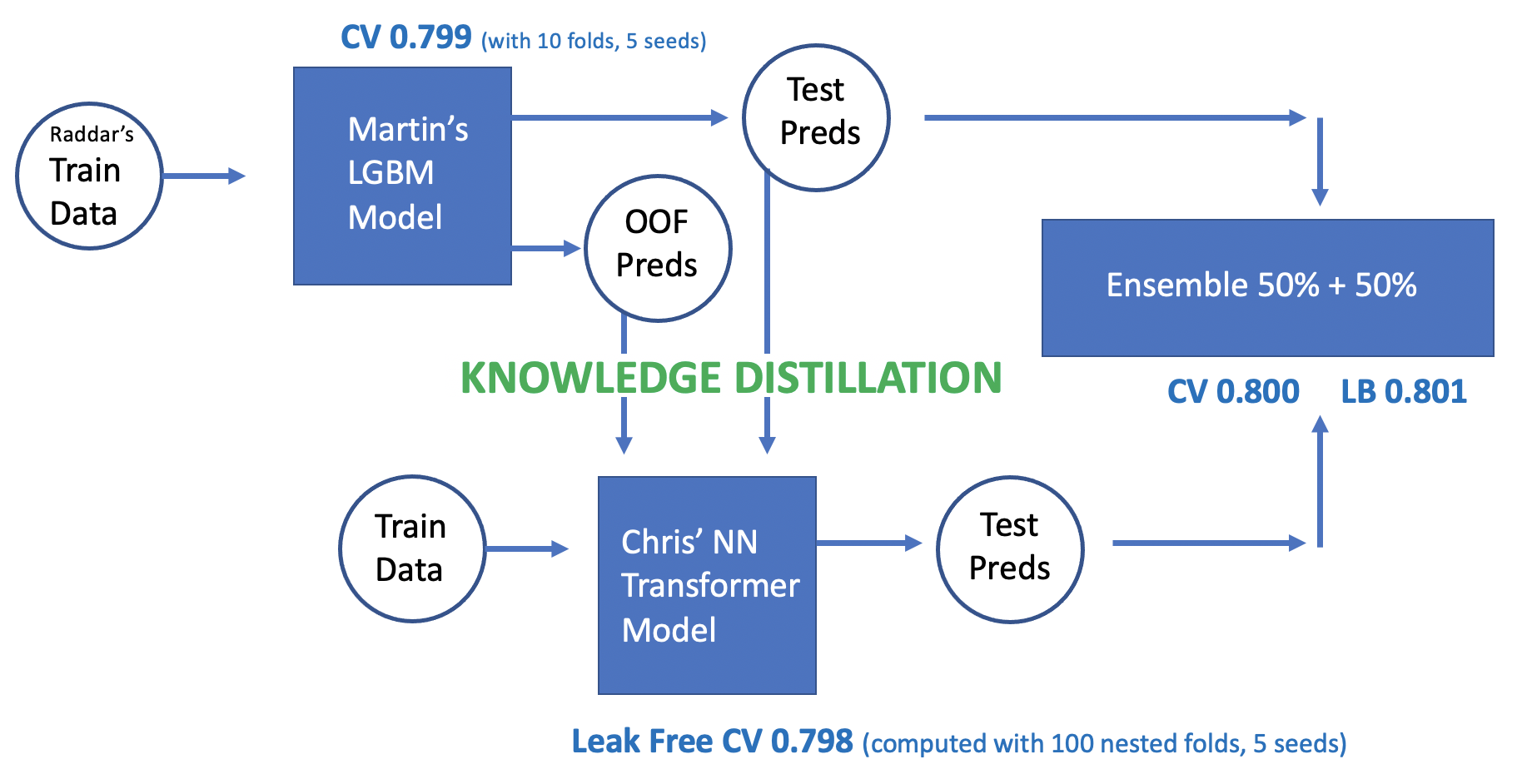
- The approach first trained LightGBM on the original data, saving the out-of-fold (OOF) predictions from cross-validation. It also used pseudo-labeling on the test set based on these OOF predictions. The OOF predictions and test predictions were then used to train a Transformer model.
- Training a Transformer model from scratch can be challenging, but with the help of knowledge distillation, the Transformer learned from the insights of LightGBM. Additionally, the large amount of test data with pseudo-labels aided the Transformer in learning. Since Transformer and LightGBM have different architectures, the attention mechanism in the Transformer learned different information, leading to better results during model fusion.
- The Transformer model was then further trained on the original training set using techniques such as nested cross-validation and seed blending.
- Finally, the outputs of LightGBM and Transformer were combined using a 50%/50% ensemble.
The second-place team also shared their solution in 2nd place solution - team JuneHomes. They mentioned that they would release the source code later. Along with the technical aspects, they also shared several best practices:
- The team used AWS compute resources for collaboration and version management of various processes (e.g., workflow version, feature engineering version, model version).
- They initially attempted manual feature engineering after removing some noise from the data, but the results were limited. Ultimately, they opted for using the statistical features mentioned earlier.
- For feature selection, they relied on LightGBM's feature importance and performed iterative feature selection using Permutation Importance, validating the results with AUC from model cross-validation. The team mentioned trying other feature selection methods but found this approach to be more stable.
- In terms of model selection, they experimented extensively and settled on LightGBM. They also built separate models for customers with fewer bills and performed ensemble modeling. The team found that stacking had minimal impact, and different seeds and feature engineering orders had little effect on the results.
- They shared their initial project plan, documenting important points and relevant resources throughout the workflow, which helped them execute their plan smoothly and achieve their well-deserved success.
The first-place solution, 1st solution, is relatively vague as the author did not provide detailed descriptions, so we won't discuss it further here.
5 Conclusion
In this competition, many useful information and techniques emerged from the Discussion section. Therefore, this article includes some essential excerpts:
- Speed Up XGB, CatBoost, and LGBM by 20x
- Which is the right feature importance?
- 11th Place Solution (LightGBM with meta features)
- 14th Place Gold Solution
Many Kagglers also shared valuable solutions. Here are some notebooks worth exploring:
- AMEX TabNetClassifier + Feature Eng [0.791]
- KerasTuner - Find the MLP for you!
- AmEx lgbm+optuna baseline
- RAPIDS cudf Feature Engineering + XGB
- Amex LGBM Dart CV 0.7977
- AMEX Rank Ensemble
I hope this sharing proves helpful to you. Feel free to leave any further questions or discussion points in the comments!